
Perceptual Video Compression
Author: Komogortsev Oleg
email:
okomogor@mcs.kent.edu,
homepage:
http://www.mcs.kent.edu/~okomogor
Prepared for Prof. Javed I. Khan
Department of Computer Science, Kent State University
Date: November 2001
Perceptual Video Compression
Author: Komogortsev Oleg
email:
okomogor@mcs.kent.edu,
homepage:
http://www.mcs.kent.edu/~okomogor
Prepared for Prof. Javed I. Khan
Department of Computer Science, Kent State University
Date: November 2001
Abstract. This work discusses different eye-gazed based compression techniques. Some issues like: positioning the high quality encoded area on the video frame, the level of degradation in the periphery, different compression techniques and approaches. It discusses the significance of the network delay for perceptual video compression.
[Keyword]: gaze-contingent video, video
compression, eye, network.
Perceptual video compression is a technique which
provides additional savings in a traditional video coding, which is based
on mathematical methods of compression and also on some constrains of the
human vision. Perceptual video compression takes into the consideration
the position of the human eye on video image, and the fact that human visual
system provides detailed information only at the point of gaze, coding
less information father from this point. There are three two
kinds of problems arise which it is: a building an accurate eye model for
the appropriate bits distribution over encoded image and the second one
is tracking eye movements to provide a careful estimation of the gaze point
on the encoded image.
Major approaches and techniques:
One of the approaches is pre-attentive approach. Idea of this approach is to determine where people have tendency to look at the image, at what areas, and later use this information to encode this processed image. [Stel95] This appraoach concludes that people have tendency to look at the same parts of the video. In this approach is divided into squares. Than the algorithm calculates the percentage of gazes which fall into each square. The squares with highest percentage contained would be encoded with high resolution and other areas would be encoded with lower one. For example these high attractive areas might be: eyes and mouth if the video is news, if video sample is fast for example it is a hockey game, than peoples attention will be attracted by the region containing the biggest amount of movements.
The other technique is to collect the VOIs
(volume of interest). VOI represents foveal loci of gaze in 3D space-time.
In general, VOI model of eye-movements distinct multiple viewers' scanpaths
into a consolidated spatio-temporal description. After the subject evaluation,
it was noticed that practically all of them followed the same pattern.
After creating the scanpaths, it is possible to pre-encode the image in
a way that a part of the image identified by the scanpaths is high quality
encoded following the HVS (human visual system) model. Implementation of
such kind of scheme might provide up to 50% compression overall in video
bandwidth, while the image degradation is imperceptible to the eye.
Real time eye-position tracking approach:
This approach assumes that exact eye position comes
from eye tracker equipment, and at any instance of time it is possible
to say exactly loaction of the eye gaze on the image. This is the most
common approach. Usually the eye position is detected by special eye-tracking
equipment [Duch01]. Than the data from eye tracker is transferred to the
video encoder, which has an algorithm of encoding eye-gaze compressed video.
This the more accurate method than the previous one, though it needs special
equipment which might be quite complicated to operate.
Let suppose that we have the exact eye position on the video image. We need to know how and where and how smoothly the video image should be degraded to provide the highest compression factor and still not be perceptible to the human eye.
Lets consider humans eye structure:
We have two quantities in our eye which built our model of vision: rods and cones. Cones are used for the color vision and they produce the most accurate-sharp picture and rods represent black and white vision:
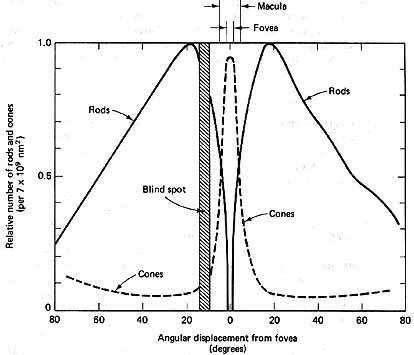 Fig. 1
Fig. 1
C. Belcher, R. Helms Lighting -
the electronic textbook
http://www.arce.ku.edu/book/
For perceptual coding cones distribution is the most essential one. Cones distribution might be represented by two dimensional graph:
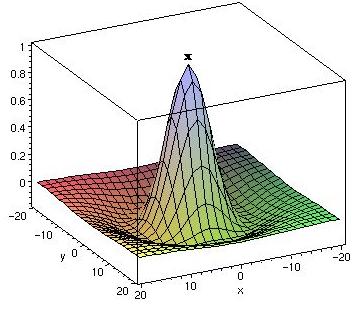 Fig. 2
Fig. 2
described by formula by the formula 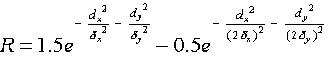 [J.
J. Kulikowski, V. Walsh, I. J. Murray Limits of Vision, Dept of Optometry
& Vision Sciences UMIST, Manchester, UK],
[J.
J. Kulikowski, V. Walsh, I. J. Murray Limits of Vision, Dept of Optometry
& Vision Sciences UMIST, Manchester, UK],
where R is response of an eye, ![]() is peak response of the unit,
is peak response of the unit,![]() is
related to width of the tuning curve.
is
related to width of the tuning curve.
Looking at this graph it is relatively easy to understand
how bits should be distributed in the perceptually encoded video image.
Point x represents the position of the human eye at given instance of
time, and most of the bits are allocated to that point. Fewer bits are
given to periphery. A picture with such bit distribution should provide
non-detectable by eye quality reduction, and also significant amount of
bits saved in encoded picture.
The base of this figure would present the acuity window
- area, which should be perceptually coded.
Written above model is HVS (human visual system). It might be hard to implement. That is why there two other models proposed linear model and non-linear model [Duch95a].
Linear model is a linear approximation of the model
written above and it easier to calculate and implement. It is also noticed
that in most cases linear model provides same results as HVS model [Duch98J1]
and [Duch98Ja]. Non-linear model is also approximation which provides overall
video quality than linear model.
Real implementations of such scheme for wavelet coding includes Voronoy partitioning of the image and providing high coefficients to the area which should be encoded with high quality. Basically Voronoy partitioning is splitting the image area with small squares resolution grid. For the center of this grid the highest coefficients are provided and for the rest of it. Resolution grid is made twice as the size of the image that allows a computationally efficient offset method to track eye position and update display without having to be recomputed the Resolution Grid each time eye moves. [Kort96].
The other practical approach is built a sequence
of images from the original image. This sequence would contain same image,
but with different decreasing sizes. For example each next image in this
sequence is four times smaller than the previous one. During encoding process
the point where eye is looking would be given pixel values from the biggest
image. The farther encoding area from the point of gaze the lower sized
images are used for encoding. Different degradation functions might be
applied while using that approach linear, non-linear or HVS acuity matching
[Duch95a].
The aspects discussed above assumes that we have exact position of the eye on the video image, but in reality eye-position should be measured by some instrument and then most probably propagated over the network, all of these components might have significant impact over the system. Let's consider the eye tracking system and the connection which supplies information to the encoder. We can imagine the general scheme for getting eye data as:
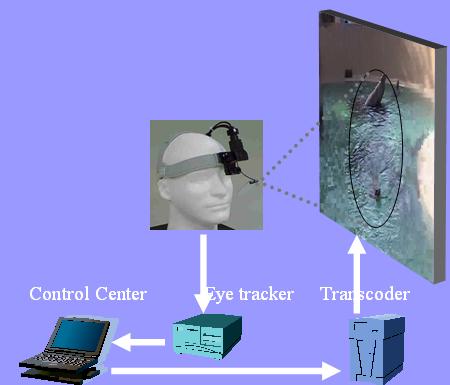 Fig. 3
Fig. 3
General system delay in this situation would be:
Delay = Eye position detection by eye tracker + control center proceeding + sending this information to transcoder + actual encoding of the image + sending and displaying encoded image
Working in the network environment such as Internet might increase sending delay greatly, which would bring more complication in the process of eye-tracking and determining exact eye position on the image.
The problem with this system is that we cannot predict
the eye position in the future, because system gets delayed information.
Therere should be way to predict future eye movements.
The good approach would be to identify eye-movements, there are three major
types: natural drift, smooth pursuit, and saccadic. Each of this type of
eye movements has their own duration time and maximum velocity. For example
natural drift are very slow (0.8-0.15deg/sec) and are present even when
observer is intentionally fixating a single point, saccades are rapid (160-300deg/sec)
movements, they appear when fixation point moves from one location to another.
Eye sensitivity during saccades is close to zero, which allows encoding
the image in a special way giving low bit-rate encoding to the whole
image area over the period when saccades occur. Smooth pursuit eye-movements
usually have velocity not greater than 8 deg/sec [Scott98].
Without having an accurate mechanism of predicting
eye movement and identifying the direction of eye-movement, it is hard
to find where all eye gazes in the future will fall.
The problem might be easily explained with the following figure:
 Fig. 4
Fig. 4
where the center of ellipse is an eye position at
the current moment and the ellipses area is the place where future eye-position
might fall. The size of this ellipse is determined by the value of delay
in the system and the current eye velocity, which in it's turn might depend
on the video content and the exact type of eye movements happening at the
current instance of time.
It is intuitively clear that the area of the ellipse should be encoded with the highest resolution, because the eye might look at any point of this ellipse. Taking in consideration delay, bits distribution graph following HVS model updated from figure 2, should look like:
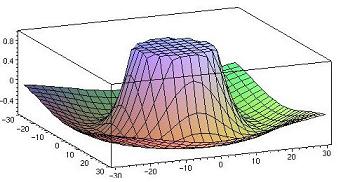 Fig. 5
Fig. 5
Having bits distributed in such way it will be possible
to contain almost all gazes in the high quality coded area.
The main question is if the perceptual video compression technique is used what is bandwidth reduction factor going to be.
Some experiments with 256x256x8gray images they where able to achieve bandwidth reduction of up to 94.7%. Reduction of the image to such a great ratio provided some artifacts, but still most of the times the perceptual video degradation was undetected by subjects [Kort96].
The other results are more moderate. Implementing
perceptual video degradation for wavelet encoding [Niu95] shows the relation
between the window size, allowable degradation, and corresponding ability
of the human eye to detect degradation. For example, if periphery quality
is degraded to a level 7 (only first seven bands of wavelet coefficients
was retained), and the dual-resolution encoded image with ROI window size
of 2 degree is presented for 150 ms to a subject then it makes the degradation
noticeable about 60% times, while a window of size 5 reduces the detection
level to less than 20% times. Though acuity window size directly affects
the amount of bits saved by the encoding algorithm. The
estimation was done for Zerotree quantization wavelet algorithm.
With 2-degree acuity window 75-65% bits can be saved, and 44-31% using
5% degree window.
Perceptual video compression is very attractive and
promising, because it provides more that 50% saved bits over already implemented
lossless compression techniques. Some factors such as implementation complexity,
predicting eye movements, reducing system delay might be drawback for this
type of compression. But considering big screens like digital theaters
and 3-D caves, perceptual video compression might be the only good solution
for reduction of humongous computations and bandwidth.
|
[Duch98M]
|
Duchowski, A.T., 3D wavelet analysis of
eye movements in Wavelet Applications V, March 1998,
SPIE.
|
|
[Duch98A]
|
Duchowski, A.T., Incorporating the viewer's point
of regard (POR) in gaze-contingent virtual environments in Stereoscopic
Displays and Virtual Reality Systems V, April 1998, SPIE.
|
|
[Duch98Jl]
|
Duchowski, A.T.,McCormick,
Bruce H., Gaze-contingent video resolution degradation in Human Vision
and Electronic Imaging III, July 1998, SPIE.
|
|
[Duch98Ja]
|
Duchowski, A.T.,
Representing multiple regions of interest with wavelets in Visual
Communications and Image Processing '98, January 1998, SPIE.
|
|
[Duch95a]
|
Duchowski, A.T.,McCormick,
Bruce H., Simple multiresolution approach for representing multiple regions
of interest (ROIs) in Visual Communications and Image Processing '95,
April 1995, SPIE.
|
|
[Duch95b]
|
Duchowski, A.T.,McCormick,
Bruce H., Preattentive considerations for gaze-contingent image processing
in Human Vision, Visual Processing, and Digital Display VI, April
1995, SPIE.
|
|
[Duch00a]
|
Duchowski, A.T., and Vertegaal, R. Course 05:
Eye-Based Integration in Graphical Systems: Theory and Practice. ACM SIGGRAPH,
New York, NY, July 2000. SIGGRAPH 2000 Course Notes, URL: <http://www.vr.clemson.edu/eyetracking/sigcourse/>,
last accessed 08/24/2001.
|
|
[Duch00b]
|
Duchowski, A.T., Acuity-Matching Resolution Degradation
Through Wavelet Coefficient Scaling. IEEE Transactions on Image Processing
9, 8. August 2000
|
|
[Duch01]
|
Hunter Murphy, Duchowski A.T, ``Gaze-Contingent
Level Of Detail Rendering'', in EuroGraphics 2001. URL:
<http://www.vr.clemson.edu/~andrewd/>,
last accessed 08/24/2001.
|
|
[Stel94]
|
Stelmach, Lew B.;Tam,
Wa James; Processing image sequences
based on eye movements in Human Vision, Visual Processing, and Digital
Display V, May 1994, SPIE.
|
|
[Stel91]
|
Stelmach, Lew B.; Tam,
Wa James; Hearty, Paul J.; Static
and dynamic spatial resolution in image coding: an investigation of eye
movementsin Human Vision,
Visual Processing, and Digital Display II, June 1991, SPIE.
|
|
[West97]
|
Westen, Stefan J.;Lagendijk,
Reginald L.;Biemond, Jan,
Spatio-temporal model of human vision for digital video compression
in Human Vision and Electronic Imaging II, June 1997, SPIE.
|
|
[Geis98]
|
Geisler, Wilson S.; Perry, Jeffrey S.; Real-time
foveated multiresolution system for low-bandwidth video communication in
Human Vision and Electronic Imaging III, July 1998, SPIE.
|
|
[Scott98]
|
Daly, Scott J., Engineering observations from
spatiovelocity and spatiotemporal visual models in Human Vision and
Electronic Imaging III, July 1998, SPIE.
|
|
[Scott95]
|
Daly, Scott J.;Matthews,
Kristine E.;Ribas-Corbera, Jordi,
Visual eccentricity models in face-based video compression
in Human Vision and Electronic Imaging IV, May 1995,
SPIE.
|
|
[Turk98]
|
Kuyel, Turker;Geisler,
Wilson S.;Ghosh, Joydeep, Retinally
reconstructed images (RRIs): digital images having a resolution match with
the human eye in Human Vision and Electronic Imaging III, July
1998, SPIE.
|
|
[Kort96]
|
Kortum, Philip;Geisler,
Wilson S., Implementation of a foveated image coding system for image
bandwidth reduction in Human Vision and Electronic Imaging, April
1996, SPIE.
|
|
[Losc00]
|
Lester C. Loschky; George W. McConkie, User performance
with gaze contingent multiresolutional displays in Eye
tracking research & applications symposium, November,
2000.
|
|
[Yoor97]
|
Seung Chul Yoon; Krishna Ratakonda; Narendra Ahuja,
Region-Based Video Coding Using A Multiscale Image Segmentation in International
Conference on Image Processing (ICIP '97), 1997.
|
This survey is based on electronic search in ACM, IEEE and SPIE digital libraries For both of this libraries following key words where used: eye gaze video compression, perceptual video compression, fovea encoded video, perceptually encoded video . Searched following digital libraries:
SPIE - www.spie.org
ACM - www.acm.org
IEEE - www.ieee.org