
Prepared for Prof. Javed I. Khan
Department of Computer Science, Kent State University
Date: December 2003
[Keyword]: lookup
protocols, peer-to-peer networks, internet, searching
What is Peer-to-Peer - Networking
Peer-to-Peer network can be thought of as the sharing recourses among multiple computers directly or without having to go through another computer (server). In this case a recourse is a hard-drive or a CPU. This is different than the traditional network where there are clients and servers. In a typical client-server network the client machine only has direct access to the server that it is connected to. If a client (user) wants to make use a recourse it doesn't have it must use the server's. In this type of network there is no way for one client to directly use the recourses of another computer that may be on the same physical network.
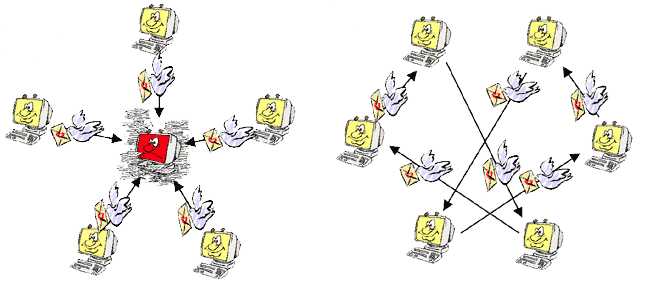
There are many advantages of Peer-to-Peer networks. For example, users can share recourses. In a typical client-server network it is apparent what some of the problems may be, first being the congestion caused by multiple clients trying to access a single server. Another is that the server may simply not have a resource that a particular client is asking for. For example, if a user wants to run a program that is on another machine on a client-server network then they simply won't be able to do it. On a Peer-to-Peer network that machine will be directly accessible by the client requesting the program, therefore able to be run. The following diagram illustrates the advantage of Peer-to-Peer communication.
 Image
courtesy of http://www.inf.ethz.ch
Image
courtesy of http://www.inf.ethz.ch
One common use with a Peer-to-Peer network the ability to have one program running on multiple machines, why do that, simply because the program may need all the recourses it can use and that one machine is not enough to accomplish the task. The most famous example of that is SETI, the Search for Extraterrestrial Intelligence. Worth mentioning here, SETI searches through terabytes of data collected from the Arecibo Radio Telescope in Puerto Rico. Normally this would be impossible for any computer to handle, even the fastest of super computers. SETI asked for volunteers to install a screen saver, which is also a program that process some of the data during that computer's idle time from the telescope. So what can my one computer do to help, not much, but though the use of Peer-to-Peer networking millions of volunteers are donating their computer's recourses and together these computers are analyzing the data. This is a very classic example of Peer-to-Peer, where computer recourses are being shared. More info on Participating
Another common use, one in which this paper focuses on, is the sharing of files. This use was made famous by Napster a web site where people could share music files. Napster could be thought of the technology that made Peer-to-Peer what it is today. After it's invention more interest was placed on Peer-to-Peer, researchers and hobbyist started to gain interest. A good site for a history time line of Napster.
This survey paper address only a small part of what Peer-to-Peer networks can do, it will concentrate on different ways in which systems perform efficient storage and searching for files over the internet and look at some systems that have either been proposed or built that accomplish that task. For each system looked at this survey will also look at an important aspect, that is, maintaining the topology or more specifically how it handles when Peers (nodes) enter and leave the system.
In many publication discussing Peer-to-Peer networks the author often refers to Napster style or Gnutella style. These styles will be explained in here for future reference.
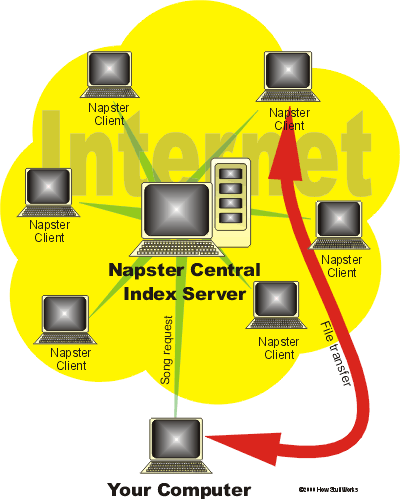 Napster style refers to a technology where there is one
central server that a user can go to find the location of a node (in
this case, a computer belonging to the Napster network) that has the
the desired file on it. For example if a user wants to find the
song Jail House Rock by Elvis Presley, the user would first go
to the Napster central server, the Napster server would then return the
address of a node that is currently holding that song. The user
would then go directly to that node and copy the song from that
node. This is illustrated in the adjacent diagram.
Napster style refers to a technology where there is one
central server that a user can go to find the location of a node (in
this case, a computer belonging to the Napster network) that has the
the desired file on it. For example if a user wants to find the
song Jail House Rock by Elvis Presley, the user would first go
to the Napster central server, the Napster server would then return the
address of a node that is currently holding that song. The user
would then go directly to that node and copy the song from that
node. This is illustrated in the adjacent diagram.
Gnutella style is another popular technology where there is no central server. In this method a user joins the Gnutella network where he/she is connected to other nodes in the network. When a file is requested, those nodes that the user is connected to are searched for that file, if it is found the address of the node containing that file is returned and a request to copy directly from that node is made. If the file is not found then the request is forwarded to from each neighboring node to all of the nodes that those are connected to, if the file is on one of those node then the address of that node containing the file is returned and a request to copy the file is made, if not found the cycle continues either until the requested file is found or the number of levels of nodes searched reaches a pre-determined limit. Below is a diagram showing how this works when the file being requested is a music file.
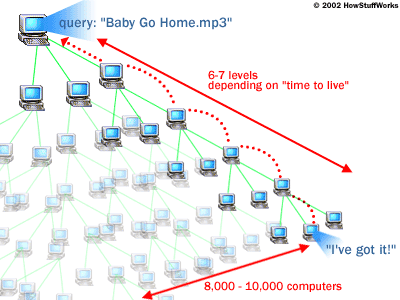
Both images are courtesy of www.howstuffworks.com
There has been a tremendous amount of research done in the area of Peer-to-Peer, as mentioned, this survey concentrates on systems where their main feature is the storage and retrieval of files on the internet. Below is selected a group of papers that discuss different methods that could be used. Each one has it advantages and disadvantages. This survey will first discuss an overview of each method then attempt to incorporate all the relevant features into a table for ease of comparison.
The following is a list of the different systems looked at:
Freenet
Overview - This system's unique feature is that it keeps a relationship between its node and the address of other nodes that are likely to hold similar information. Freenet nodes hold 3 types of information , keys (web URLs), addresses of the other similar keys, and optionally the data corresponding to those keys.
Algorithm for getting data - How it works is a user puts a request for a file, his/her node sends a request to a node it knows about. If the requested file is not there then that node will return that it doesn't have it and it will also return the keys that are more likely to have the requested file. The user's node will then search those nodes, if none of them have the file, then the same as the first result, they will return that it is not found and likely keys (nodes/URLs) that are likely to have the requested data. This cycle will continue until the file is found.
This may sound like an incredible time-consuming procedure, but the advantage is that every time there is a successful find, the keys are updated, so the more the system is used the more efficient it will become because more nodes will be holding key relationships that have a high probability of locating requested files.
Handling when nodes enter and leave - To join the system a node sends an announcement to some node that is found by an out of network method such as personal communication or list on a web site. This new node randomly locates other nodes and updates all of their routing tables of the location of the new node. Similar to the Gnutella style, when it leaves, probes to the dead node will be noted and routing tables adjusted accordingly.
CAN
Overview - Content-Addressable Network (CAN), CAN is a way for peer-to-peer systems to have a scaleable indexing system for P2P (Peer-to-Peer) searches over the internet. The main tasks are insertion, deletion, and lookup of any key pair, i.e.. (file, location). CAN creates a virtual coordinate system with the points in that system representing files. When searching for a file the request is mapped to a point P in the logical Cartesian coordinate system. Once at node P, then the key is looked up in a Hash table that eventually returns the location of the node which has the file.
Algorithm for getting data - Each CAN node will store a chunk or a "zone" of the virtual coordinates in a hash table. Each CAN node will also store information about it's adjacent CAN nodes. In it's coordinate zone it maintains a routing table that holds the IP address and virtual coordinate coordinate zone of each of its immediate neighbors. Nodes are neighbors if they share a border and abut along another axis. When sending out a request, a CAN message will include the destination coordinates, and using a simple greedy algorithm forward to the coordinates closest to the destination coordinates. Note that there will be many available paths to neighbors, this is good because if a node leaves the network, another path can be used. The case where all of the nodes in a certain direction fail then the system searches fail. After the system detects this failure a node will expand its search ring using controlled flooding over the CAN overlay to locate an available node. The message will then be forwarded in the normal fashion until the desired node is found.
Handling when nodes enters and leaves - As described above the entire CAN topology is broken up into zones. When a new user/node enters into the system it must be given it's own zone. This is done by an existing node giving half of it's zone to the new node. The steps include: 1. a new node finds an existing node in the CAN topology. 2. From that starting point, search the CAN network for a good candidate zone to be split and split the node. 3. Notify all the neighbors of the new zone so that routing will include that node. The very initial entering of a node is handled by a user going to a DNS domain name and randomly selecting one of many nodes that are known to be in the CAN network. From there it forwards it's request. This is referred to as the boot-strap node.
When a node departs it's zone must be maintained. It searches it's neighbors for a likely candidate, if one is available it simply merges it's zone with the neighbor's to form a new zone. If there is no likely candidate node then the neighboring node with the smallest zone is selected to force a merger of zones. This is only temporary until a CAN topology update occurs and the zone is merged with a better node.
There's the case when a node has a failure and drops out instantly. Nodes send periodic messages to it's neighbors, if a node has not received one in a while it assumes that node is dropped and begins a take over mechanism whereby searching and adding the deleted node's key,value pairs to it's own zone. Each neighbor of the failed node will do this. In addition, each takeover node starts a timer. When the first neighbor finishes the take over it sends a TAKEOVER message to all the neighbors saying that it has finished. The others drop their takeover attempt.
GIA
Overview - The main idea of this paper is to make a Gnutella style of Peer-to-Peer network more scaleable in terms of number of nodes searched and speed. This paper looks at a variety of approaches to the traditional Gnutella style and incorporates them into one new system called GIA. Two main approaches are the use of "supernodes" which are nodes that have high bandwidth and have a large store of searched data, and biased random hops instead of strictly searching neighboring nodes.
Algorithm for getting data - Similar to Gnutella style of flooding. Once a request has been initiated it will select the highest capacity neighbor and forward the query to that neighbor, if not found there then that neighbor will then forward it to it's neighbors. This cycle will continue until the file is found or TTL is reached. The TTL is a Time To Live value that limits the duration of the nodes being searched. Gia also gives each search a unique identifier so that if a node it searched twice with the same identifier it will forward it on a different path to avoid cycles.
Another way in which GIA differs from Gnutella is that each of the nodes in the system stores an index of the content of each of its neighbors. That way when a node is probed it can return the matches of itself and its neighbor's.
Handling when nodes enter and leave - When first entering the system it uses a bootstrapping mechanism similar to Gnutella to locate other Gia nodes. Each node will have a cache of other Gia nodes. Gia also employs a rating mechanism where it maintains satisfaction level. If a node is dissatisfied for a given amount of time the it can get a new neighbor.
Node departure is one of the best features of this style. Since each node keeps track of several neighbors, when a node departs the only thing that needs to happen is for the deleted node's neighbors to realize that it's gone and not to forward any queries to that node. The cache of neighboring nodes are updated periodically to refresh.
Yappers
Overview - This method uses a combination of Gnutella-Style and Distributed Hash table. In addition in groups the nodes according to some attribute that they have in common. What is unique to Yappers is the combination of the above 3 features into one P2P system. It can do total lookups on every node in the network and at the same time limit which nodes to search relative to the type of information being searched. As with some of the other methodologies it has the notion of neighborhoods where nodes are grouped together. Each neighborhood will have a central node containing the hash table of keys for that neighborhood and each neighborhood is aware of it's neighbors. In addition there is the concept of an extended neighborhood. These are used for full searching and larger jumps in searches.
Algorithm for getting data - First thing Yappers must do is categorize the search. It does this so it knows which nodes to search on. For example if the user is looking for music files then it will not consider any nodes that are known to only contain video files. Yappers forms a "sub-network" per category. When the search initiates, the immediate neighbors are contacted, this is the Gnutella portion of the search, with each node it contacts it looks at that neighborhood's hash table to see if the desired file is there, if not it will branch to the next node or nodes. It will do this until the entire Yappers network is searched. It prevents cyclic searching by using a search request number and each neighborhood remembering if that search has visited it yet.
Handling when nodes enter and leave - When a node wants to join the Yappers network the Yappers topology must readjust the immediate neighborhoods and extended neighborhoods of the ones it joins. It makes a selection based on the size of available neighborhoods and type of data being stored in that node. Yappers actually wants a variety of types of nodes in each neighborhood, this helps the interconnection among other neighborhoods.
When a node leaves it must broadcast the deletion to a field of nodes two times hops away. For example h=3 or 6 hops. Each Yappers node updates the topology and adjusts it's immediate and extended neighborhood accordingly. Each still existing node in the neighborhood will have to find another node to re-add it’s (key, value) to that was previously stored on the deleted node.
Chord
Overview - The software is a library that is linked with a client and server applications that are going to use it.
Algorithm for getting data - Chord sets up a virtual ring of nodes. Once a search is initiated from a node it looks to it's successor node, which will be the next node on the circle. If what the user is looking for is not there then the search is directed down the successors nodes finger table, which is a routing table. This is more than simply searching the next node, it contains the (key, node) pairs of nodes that are further down the circle. As the request moves around the circle it searches these finger nodes until the desired match is found or the search goes beyond the key. It then has narrowed down where the item is and works backward from there until if finds it.
Handling when nodes enter and leave - when a new node is added Chord runs through the following steps: 1. Initialize the new node finger table. this is done with the next 3 steps, 1. locate any node p in the ring, 2. ask node p to lookup fingers of new node then 3. return results to new node. Afterwards Chord will have to update the fingers of the existing nodes, telling about the new node. This is done by 1. the new node calls an update function on existing nodes and the existing nodes will recursively update fingers of other nodes. Now the new node needs keys therefore chord will transfer keys from successor node to new node of a certain range
How a node departure is handled. Chord will implicitly use the successor list of the node that departed by using the successor list of the node previous to the departed node. After the failure the chord network will know its first live successor from that list. The path traversal will continue using that list. The only issue is that some nodes that were listed in the departed node's list will not be searched until chord initiates a update.
SETS
Overview - This paper focuses on increasing searching efficiency by arranging sites such that queries will probe small subset of sites based on the topic being searched. This paper is intentionally at the end of the list because it does not discuss a specific new way of searching which is the intent of this survey, reading the preceding discussion will simplify some of the aspects of this paper. This paper is included in this survey because it's interesting approach. It discusses the idea of no matter how you search, that it should be done by first grouping related information in the data set. This takes a novel approach in that it suggest placing nodes in the network based on content. Hence the name SETS - Search Enhanced by Topic Segmentation. Most of the paper deals with breaking the network into segments and then determining how to categorize nodes into segments. A segment be a area on the network of related information.
Algorithm for getting data - In the paper the authors use the Gnutella style of flooding for data retrieval..
Handling when nodes enter and leave - A central server is contacted which determines which segment the node should be in based on the type of content that node has. The new node then establishes short links with m number of nodes that are chosen randomly from among current members of a segment. A departing site simply terminates its links, similar to Gnutella style.
Summary Table: The following is a table comparing the relevant features of each of the systems.
| Protocol Name | Type of Search Technique | What Part is Centralized | Degree of Decentralization | Potential
Points of Vulnerability/Availability |
| Gnutella-Style | Blind Flooding |
None |
100% |
Limited in search, not scalable. |
| Napster-Style | Hash |
Server containing pairs (File name, IP Address) |
Actual copying of file is true P2P, but has a central index server. |
Uses a single repository index. If Napster web site is down no-one gets file. |
| Freenet | Smart Flooding |
None |
100% |
Can be very network transmission intensive. |
| Can | Flooding on Hash |
None except the initial Boot-Strap server when a user goes to join the system. |
100%, except a boot-strap node where new node first go. |
If all nodes of the neighboring zone leave, temporary loss of connectivity occurs. Many sudden losses of nodes causes unusual delayed reconfiguration of the system. If Boot-strap server is down no-one can enter. |
| Gia | Flooding |
None |
100% |
May not find the file being searched even though it is in the system. Potential bottleneck at the supernodes |
| Yappers | Flooding on Hash |
None |
Partial. Each neighborhood will have a node that has the Hash table index. |
There is potential of a large fan out of the topology where there is a lot of breadth and not much depth. |
| Chord | Hash |
None |
100% |
Worst case lookups can be
very slow.
Failure of nodes may cause incorrect lookup Failure of many consecutive nodes in the same direction may stop a lookup. |
| Sets | Smart Flooding |
A server that determines which segment a node should belong to. |
Partial. Mostly true P2P except for the initial placement of the node. |
Limited in search, not scalable. |
| Protocol Name | Scalable Index |
Node Enters | Node Leaves | Research Suggestion or Implemented Already |
| Gnutella-Style | No |
Joins the network, recognizes several adjacent nodes. |
Errors returned when trying to send to a non-existing node. Neighboring nodes update there link. | Implemented, very popular and used widely throughout the Internet |
| Napster-Style | Yes |
Joins the network, address and list of available files are stored on central server. |
Index on the server is updated. Search returns a not found, goes to next node that matches the request. | Implemented, very popular and used widely throughout the Internet |
| Freenet | Yes | Locate an initial node, That node randomly selects other nodes to update their routing tables of the new node's existence | Nodes notice dead link and update their routing tables. | Implemented, very popular and used widely throughout the internet. Often used to post anomalously. |
| Can | Yes | Run algorithm to select a good candidate to split a zone with, split the zone and assign new zone to new node. | Lost node is discovered by neighbors, these neighbors decide who will be assigned the departed node's zone, then a merger of the 2 zones occurs. | Implemented, Actually implemented as a part of other systems that do not run on the Internet. |
| Gia | No, but improved over Gnutella | Bootstrap routine is run and adds the node to the system, it notifies nearest neighbors of it's presents and adds them to it's list. | Nothing, as long as all the neighboring nodes do not leave requests are simply forwarded to another node. | Implemented a prototype. Tested against similar protocols on wide-area service deployment testbed. |
| Yappers | Yes |
Notify neighboring nodes. Reconfigures a new neighborhood broadcasting the information 2h (hops) nodes away. |
When an edge is deleted, YAPPERS would notify every node in the immediate neighborhoods of the nodes where the edge was deleted. These nodes would then know that a connection was lost, not to try a query thought that edge and also try and find another node to join their IN to maintain the YAPPERS topology. |
Paper indicates its been implemented and run against a network simulator. Not in popular use. |
| Chord | Yes | Find a likely place in the circle. Get the neighboring nodes finger table, use it temporarily for the new node, update all of the nodes of the new node. This will re-propagate the lookup structure. | Use it's successor's finger table for next link. Do this until chord initiates a update among the nodes. | Implemented in a small internet testbed. |
| Sets | No | simply notifies neighbors of it's segment | Terminates its the links | Research Suggestion |
In summary it seems that all of the P2P searching algorithms are either flooding or distributed hash tables. There are advantages and disadvantages to both. The DHTs are much more efficient in their speed of lookup and are scaleable in their search. But these systems have a large overhead to maintain the topology, especially when a node enters and leaves. Even more so when a node does not leave gracefully. In addition the search keys in a DHT have to be more precise because of the exact matching that must occur in the key, address pair. Whereas flooding approach can more easily take the search engine approach and find close matches. Flooding mechanisms also have the drawback of not having a scaleable search and an inefficient method of searching. That being said they have the advantage of low overhead when a node enters and leaves the network. If we look at what the internet is doing, the flooding approach is much more popular.
Conclusion:
Some of the overall research challenges are to make the searching faster, more relevant and complete. Also a big challenge is making these systems popular and usable over the internet. Right now very few are actually being implemented on the internet, it would be interesting to see how well these systems, especially the distributed hash methods, would work with millions of users over the internet. An interesting research area would be, once implemented, to analyze how these systems use internet recourses and look at different ways in which they could be modified to be more efficient and reliable.
2.
Chord:
A scalable peer-to-peer lookup service for internet applications
Ion Stoica, Robert Morris, David Karger, M. Frans Kaashoek, Hari
Balakrishnany
August 2001 - Proceedings of the 2001 conference on Applications,
technologies, architectures, and protocols for computer communications
3.
A
scalable content-addressable network,
S. Ratnasamy, P. Francis, M. Handley, R. Karp, and S. Shenker
Proc. ACM SIGCOMM, San Diego, CA, Aug. 2001, pp. 161–172
4.
Peer-to-peer:
Making gnutella-like P2P systems scalable
Yatin Chawathe, Sylvia Ratnasamy, Lee Breslau, Nick Lanham, Scott
Shenker
August 2003 - Proceedings of the 2003 conference on Applications,
technologies, architectures, and protocols for computer communications
5.
Distributed
information retrieval: SETS: search enhanced by topic segmentation
Mayank Bawa, Gurmeet Singh Manku, Prabhakar Raghavan
July 2003 - Proceedings of the 26th annual international ACM SIGIR
conference on Research and development in information retrieval
3.
YAPPERS: A
Peer-to-Peer Lookup Service over Arbitrary Topology
Prasanna Ganesan Qixiang Sun Hector Garcia-Molina
3rd International Workshop on Peer-to-Peer Systems (IPTPS '04)