
Adaptive
Quality Of Service For Internet Telephony
Olufunke
Olaleye
email: oolaleye@cs.kent.edu,
homepage: http://www.cs.kent.edu/~oolaleye
Prepared for Prof.
Javed I. Khan
Department of Computer Science, Kent State University
Date: December 2003
Abstract: The quality of voice
over IP is dependent on the delay, packet loss and transmission rate,
finding
an optimal method has been a challenge. There are various techniques
for
adapting the transmission of voice packets over the internet while
maintaining
the end-to-end perceived quality of audio. Among these are the path
diversity,
loss concealment, forward error correction, and transmission rate. In
this
paper, we compare the different approaches that have been used to
improve the
impact of end-to-end quality of service from a perceived audio at an
acceptable
level.
Other
Survey's on Internetwork-based Applications
Back to Javed I. Khan's Home
Page
Table of
Contents:
Introduction
How it works, its applications
The
Adaptive Method
Classification
and Types
Congestion
Control Methods
Measuring Models
Adaptive
Techniques
Joint
rate/error/playout delay adaptation algorithm
Joint source and channel coding adaptation
algorithm
Multi-path
transmission
Summary
References
Research Papers
for More Information on VoIP
Research Groups
Other
Relevant
Links
Scope of Survey
Introduction
What
is VoIP?
VoIP (voice over IP) simply mean voice transmission over the Internet using the Internet Protocol. It is the transmission of voice traffic in packet, this means sending voice stream in discrete packets instead of the regular analogue form of the traditional circuit-committed protocols of the public switched telephone network. (PSTN). Since, IP operates in both wide area network (WAN) and local area network (LAN), it therefore mean VoIP can work on any network.
One major advantage of VoIP is that it is cheap, since it bypasses the tolls charged by ordinary telephone service. It utilizes the Internet backbone, thus avoiding the long distance traffic of original telephone services.
Voice over IP uses the real-time protocol (RTP) to guarantee that packets are delivered in a very short period time. It uses Real time control protocol (RTCP) provides delivery feedback. RTCP VoIP also uses other protocol like Resource Reservation Protocol (RSVP), H.323 and Media Gateway Control Protocol (MGCP). H.323 is a standard for sending voice and video using IP on the public Internet and within an intranet.
Some major equipment providers like Cisco, VocalTec, and 3Com uses H.323 protocol.
How it works, its
applications
VoIP uses packet switching method to transmit voice stream from the sender to the receiver. In packet switching, a voice steam is broken into smaller piece called packet. The voice signal is digitized, compressed and converted to IP packets. Each packet header is labeled with source address, destination address and packet numbering. The packets are sent individual across the Internet, which may take different route to the destination. The packets arrive at the destination and they are reassembled into original voice stream.
Signaling protocol that carries information required to locate users and negotiate capabilities performs the call set up and call tear down. Other packet switching techniques are ATM, and Frame-relay. In Packet switching, there is no dedication communication line from source to destination rather packets are sent through different routes. Fig 1 shows the end-to-end transmission from sender to receiver.
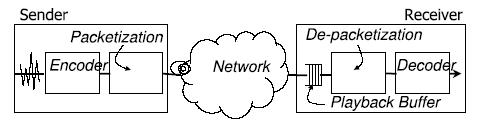
Fig. 1. End-to-end
transmission for voice packet
Limitations
of VoIP
Real time audio transmission is widely used in today’s Internet. The major challenge of voice over IP is quality of service (QoS). This is a very important issue.
The best effort network was originally designed for data communication. The delivery of data in best effort network does not guarantee delivery of packet; this is not the same for audio, because it is delay sensitive. Internet protocol suite is not designed to accommodate synchronous, real-time traffic, such as voice. The audio (voice) quality degrades when the packet crosses a loaded part of the Internet.
A number of factor that affect the quality of service are packet loss, delay and jitter (delay variation). Jitter is often resolved by adaptive playout algorithm at the receiver’s end.
As VoIP is a delay-sensitive application, a well-engineered, end-to-end network is necessary to use VoIP successfully. For VoIP to become acceptable to users, the end-to-end delay needs to the threshold value of 150ms. The IETF (Internet Engineering Task Force) is working on this aspect.
The Adaptive Method
Classification and Types
There are various recovery techniques used in VoIP to improve the quality of perceived voice, in order to minimize the effect of packet loss, delay, jitter and computation complexity.
These are classified into sender-based and receiver-based recovery technique.
Sender-based technique is the adaptation that occurs at the sender’s end. This includes Forward Error Correction (FEC), Source and Channel coding and interleaving. The adaptation at the sender’s end may introduce delay and also cannot recover all packet loss.
Receiver-based technique is the adaptation that occurs at the receiver’s end. The adaptation at this end does not introduce delay. More importantly, they are not dependent on the sender’s recovery technique. Example of the receiver-based technique includes Loss concealment and Double Sided Pitch Waveform Replications (DSPWR).
Congestion Control Method
The audio application shares resources fairly with each other and with current TCP-based applications. To ensure a fair resource sharing, one needs to implement some form of congestion control that adapts the transmission rate and is TCP-friendly congestion control [12].
There are some
TCP-friendly control
mechanisms and many control schemes that has been researched on. The
following
scheme has been used.
Lossy environment: Retransmission
Retransmission, which is based on Automatic Repeat Request (ARQ) has been successful in TCP (Transmission Control Protocol). However, due to the sensitivity of the voice over the Internet, retransmission is not suitable for VoIP. It is not appropriate for real-time application like voice. This is because it increases the end-to-end delay of RTT between sender and receiver thereby exceeding the allowable delay of 150ms for interactive applications like voice. Alternative to ARQ is FEC.
Channel Coding: FEC
Forward Error Correction (FEC) is another recovery technique. It transmits redundant information of each packet in subsequent packets. A lost packet can be recovered from the redundant copies piggy backed to subsequent packets.
The FEC technique is further classified into two, the media specific and the media independence. The FEC media specific transmit each segment of audio, encoded with different quality coders, in multiple packets. Once a packet is lost, the receiver uses the redundant information containing the same segment to reconstruct the lost information. Fig 2 shows a simple FEC technique (Media-specific FEC) where packet n carries the redundancy of packet (n-1). As show in this diagram, packet 3 was lost, but the preceding packet, packet 4 was used to reconstruct the stream. Packet 4 carries redundant packet 3 along with it.
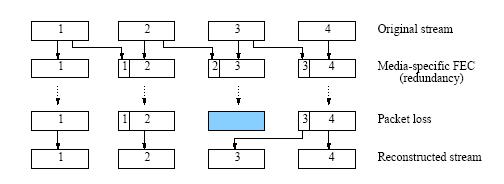
Fig 2. The simple FEC technique (Media-specific FEC) where packet n carries the redundancy of packet (n-1)
Normally, for a single redundant segment, packet n contains, in addition to its encoded samples, a redundant packet n – 1, though this could be in a lower bit rate. It however adds delay to the network. [4], [6] indicates that this type of technique is not viable because of increase in delay at the expense of bandwidth. The FEC media specific is limited by delay budget.
The FEC media technique uses the block codes based on Reed Solomon [9] or on parity codes [10] to provide redundant information. Reed-Solomon code (RS) codes are a special class of non-binary linear codes. In RS, (n, k) codeword consist of k data packet that generates (n – k) redundant check packets for transmission of n packets over the network. The redundant check packets are placed in separate packets. These techniques have the advantage of recovering the lost packet in a bit-exact way. Fig 3 shows the RS (n, k) codeword
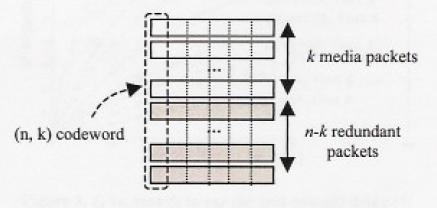
Fig 3. (n,k) RS encoding
across packet
In general, FEC efficiency is limited on a single path with bursty loss [2]. FEC is more efficient when the consecutive number of packet is small.
Loss concealment
Loss concealment algorithm is used to correct losses that FEC fails to recover. It uses repair mechanism like insertion, interpolation or regeneration. Loss concealment algorithm [7] is a method for exploiting inter-channel redundancy in order conceals losses in a channel with the substitution from other channels by appropriating packetizing the stream. It interpolates among different channel to derive a waveform substitution for a lost session, instead of using sample from same channel.
Source-coding
From source coding perspective, a source and channel rate
adaptation algorithm has been prospered; it
adapts its bit rate to the available bandwidth [2]
to
maximize a subjective quality. The algorithm used does not consist of
predefined combinations but rather determines the optimal solution
given
specific constraints on the maximum delay, packet loss, and allowed
bandwidth.
It exploits the multi-rate capability of adaptive multi-rate codec
along with
media-independent FEC.
Multiple Path Scheme: Path diversity
Sending packets simultaneously over multiple paths to overcome the unpredictability and congestion of the Internet. Path diversity has been proposed in [3] to improve the quality of real-time voice communication. It sends multiple redundant descriptions of the voice stream over different independent paths, instead of restricting transmission to one network. It takes advantage of their largely uncorrelated loss and delay characteristics.
Interleaving
Interleaving in [11] is a sender-based loss recovery technique. Interleaving provides an effective means by which audio streams may be protected which trades latency, rather than bandwidth.
The advantage of this technique is that it does not increase data rate of transmission. It’s efficiency is dependent on the number of packet the source interleaves and spread.
Double Sided Pitch Waveform Replications
DSPWR [5] is a sophisticated recovery method that can tolerate a much higher packet loss rate with less computation. It resolves the delay due to processing.
Priority Queuing
Priority Queuing (PQ) in [13] is used to improve QoS by giving higher priority to voice packets to alleviate delay of VoIP in the network.
Protocol: Equation based rate control
Equation based rate control compete fairly with other TCP traffic for bandwidth stabilizing the throughput and reducing jitter. TCP-Friendly rate control used in [1] relies on the Real-Time Transport Protocol (RTP) [13] and RTCP control report. The source performs equation based congestion control based on feedback information contained in RTCP reports and adjusts its sending rate by changing the packet size [8], the time interval (jitter) between packets remaining fixed. This is an interesting adaptive method.
This method performs better than others especially where end-to-end delay is important.
Measuring
Models
The
Gilbert model
Due
to the bursty nature of the Internet, the Gilbert model
is often used to describe the bursty losses because of its accuracy. It
has two parameter p and q. The Gilbert model is a two-state model in
which
state 0 represents a packet reaching the destination and state 1
represents a
packet loss. The parameters p and q indicate the
probabilities of
passing from state 0 (no loss) to state 1 (loss) and from state 1 to
state 0
respectively.
When FEC is not used the
packet loss rate PLR
= p / (p+q)
The
E-model
E-model is use to measure the quality of voice. It predicts the subjective quality that an average listener experience by combining the impairment caused by transmission parameter into a single rating.
The output of the model is a rating value that could be used to predict the subjective user reaction called MOS or a rating could be scalar quantity called the R factor. Rating R on a scalar quality ranges from 0 to 100 where R = 100 indicates a very high quality and R = 0 indicates a bad quality. Value is an analytical estimate of subjective score. MOS value range from 1 to 4.5, where 1 represent a poor quality and 4.5 best quality.
E-model Rating R is defined as
R= Ro
- Is - Id - Ie + A
Ro= noise effect
Is = Impairment due to quantization
Id = Impairment of delay
Ie = signal distortion (low bit rate
codec & packet loss)
A= the advantage factor that some
user are willing to tolerate quality reduction due to mobile telephony.
For voice traffic, the R- factor is given by [1], [4]:
R
= 94.2 – (Id – Ie)
Adaptive
Techniques
[1] developed a joint rate/error/playout
delay control algorithm that optimizes the perceived audio quality,
that is
TCP-Friendly. It uses a channel model for both loss and delay. It relies on the Real-Time Transport Protocol
(RTP) [13] and RTCP control report.
The source performs
equation based congestion control based on feedback
information contained in RTCP reports and adjusts its sending rate by
changing the
packet size [8], the time interval (jitter)
between
packets remaining fixed. It allows
source to increase its utility by avoiding an increase of the playout
delay
when it is not really necessary.
The parameters of
optimization are playout delay and FEC. It jointly
chooses the playout delay and FEC method.
[2]
developed a joint source and channel coding adaptation
algorithm for AMR
that optimizes the perceived audio quality. It adapts the codec bit
rate to the
changing network conditions in order to preserve acceptable levels of
quality.
The E-model shows
that increasing delay indicates reducing the MOS value
while decreasing packet loss indicates increasing the MOS value. Codec
rate adaptation
is an effective method to mitigate the effect of packet loss due to
network
congestion.
Allowed bandwidth
reflects the constraint set by the congestion control
policy on the maximum allowed speed. The congestion control algorithm
converges
to the available bandwidth of the path. The allowed bandwidth is the
available
bandwidth in [2]. It derive the end-to-end
delay and
uses a single speech codec It
exploits the multi-rate capability of adaptive multi-rate codec along
with
media-independent FEC within respect to packet loss within specific
constraints. The algorithm finds a compromise between packet loss
recovery and
end-to-end delay to maximize perceived audio quality.
The parameters of
optimization are source and channel bit rate.
[3] developed a multi-path transmission of real-time voice using multiple redundant descriptions of voice stream that are sent over independent network paths. Scheduling the playout of the received voice packets is based on multi-stream adaptive playout scheduling that uses a Larangian cost function to trade delay for loss.
It takes advantage of their largely uncorrelated loss and delay characteristics.
The multiple streams that are
transmitted along different paths are formed by multiple description
code
(MDC), which generate multiple descriptions of the source signal of
equal
importance. These descriptions can be
decoded independently at the receiver. If all descriptions are
received, the
source signal can be reconstructed in full quality. If we receive only
a subset
of the descriptions, the quality of the reconstruction is
degraded, but is
still better than the quality resulting from losing all
descriptions. The
overall data rate of the payload does not necessarily increase as a
result of
transmitting multiple streams. The data rate only increases if we
desire redundancy
between the multiple streams.
Disadvantage of this technique is that if there is a subset of the descriptions, the quality of the voice is degraded. If FEC is used with this technique, then there will be high bandwidth utilization. There is no congestion control mechanism in this approach; the approached really on fact that multi-path are largely uncorrelated.
The parameter of
optimization is the playout deadline, which is the time
from a packet is delivered to the network until it is playout.
Summary
Arriving at a high quality of service for Internet telephony has been a challenge in the IT industry. This principal reason for this statement is that the Internet protocol suite is not designed to accommodate synchronous, real-time traffic, such as voice. In addition, the packet loss experienced in IP networks as well the delay and jitter militates against effective support of voice packet.
The quality of voice over IP is dependent on the delay, packet loss and transmission rate, finding an optimal method is a challenge. There are various techniques for adapting the transmission of voice packets over the Internet while maintaining the end-to-end perceived quality of audio.
In this paper, we compared the different approaches that have been used to improve the impact of end-to-end quality of service from a perceived audio at an acceptable level. Adaptation that relies on real time protocol would be an appropriate adaptation for voice over IP.
RTP was designed for real-time traffic that needs to be sent and received in a short period. [1] has developed an adaptation algorithm to meet this challenge. It relies on the Real-Time Transport Protocol (RTP) [13] and RTCP control report. The source performs equation based congestion control based on feedback information contained in RTCP reports and adjusts its sending rate by changing the packet size [8], the time interval (jitter) between packets remaining fixed. It allows source to increase its utility by avoiding an increase of the playout delay when it is not really necessary. [1] has succeeded in trading delay for losses.
However, there is however still need for more sophisticated method to reduce delay.
Reference
Research Papers For Information on VoIP
[1] Catherine Boutremans, Jean-Yve L Boudec, “Adaptive Joint Playout Buffer and FEC adjustment for the Internet Telephony,” 2003.
[2] Johnny Matta, Christine Pepin, Khosrow Lashkari, Ravi Jain, “A source and channel rate adaptation algorithm for AMR in VoIP using E-model,” June 2003.
[3] Yi J. Liang, Eckehard G. Steinbach, Bernd Girod, “Voice over IP: Real-time voice communication over the Internet using packet path diversity,” October 2001.
[4] Wenyu Jiang, Hening Schulzrinne, “VoIP: Comparision and optimatization of packet loss repair methods in VoIP perceived quality under bursty loss,” May 2002.
[5] Wen-Tsai Liao, Janet J.C.Chen, Ming-Syan Chen Chen, “Adaptive Recovery Techniques for Real Time Audio Stream”
[6] Eitan Altman, Chadi Barakat, Victor Ramos, “Queuing Analysis of Simple FEC schemes for IP Telephony,” 2001.
[7] Rishi Sinha, Christos Paradopoulos, Chris Kyriakakis, “Loss Concealment for Multi-channel streaming audio,” June 2003.
[8] Fabrice Poppe, Danny De Vleeshauwer, Guido Petit, “Choosing the UMTS Air interface Parameters, the Voice Packet size and the Dejittering Delay for a Voice-over-IP call between a UMTS and a PSTN party,”
[9] R. Blahut, Theory and Practice of Error control codes. Addison-Wesley,1993.
[10] N. Shacham and P.M Kenney, “Packet recovery in high-speed networks using coding and buffer management,” in Proc. IEEE Infocom 1999
[11] Colin Perkins and Jon Crowcroft, “Effect of Interleaving on RTP Header Compression,”
[12] J.
Mahdavi and S. Floyd, “TCP-Friendly unicast
rate-based flow control,” in Draft posted on end2end mailing list,
January
1997, http://www.psc.edu/networking/papers/tcp
friendly.html.
[13]
H. Schulzrinne, S. Casner, R.
Frederick, and V.
Jacobson, “RTP: A transport protocol for real-time applications,” RFC
1889,
1996.
Research Groups
AT&T LAB Research group
AT&T LAB Research group currently is working on the VPlus project, investigating how to build advanced VoIP network-based services and features. http://www.research.att.com
Infotech Research group
Telecom Synergy Research Group
The group presents the Voice over IP (VoIP) infrastructure equipment measuring
markets of Private
Enterprise Networks and "Public" Service Provider Networks. The
market coverage focuses on LAN Telephony, Enterprise Gateways - Servers
& Routers,
Service Provider Gateways - Standalones & Concentrators,
Low-Density
Gateways, Mid-Density Gateways, and High Density Gateways.
http://www.telecom-research.com
NASA: Flight Deck Display Research Group http://human-factors.arc.nasa.gov
NASA: Flight Deck Display Research Group is working on Flight Simulation using Voice over Internet Protocol (FS-VoIP). Communications during a flight simulation must be reliable.
http://human-factors.arc.nasa.gov
Lucent Technologies
Acuity Research Group
Acuity Research Group is working on a project on VoIP; they used a simulated-sales technique to obtain feedback from about 50 enterprise customers concerning the business justifiability of moving to a VOIP solution.
http://www.acuityresearchgroup.com
Other Relevant Links
- VoIP Tutorials http://www.voiptimes.com/research/tutorials/
- IP Telephony and Protocol http://www.cisco.com/en/US/tech/tk652/tk701/tech_protocol_family_home.html
- Voice and Fax over IP http://www.iec.org/online/tutorials/vfoip
- SS7/IP Interworking http://www.pt.com/tutorials/iptelephony
- VoIP Howto http://www.linuxanswers.net/index.php?cmd=howto&key=voip
- Quality of Service http://www.cisco.com/univercd/cc/td/doc/cisintwk/ito_doc/qos.htm
- VoIP Solutions http://www.iptelephony.org/GIP/vendors/qos
Scope of Survey
This survey is based on electronic search in ACM's digital library, IEEE Infocom proceeding, and their citations. The ACM's digital library was searched using key words 'VoIP', ‘QoS’, ‘FEC’, ‘RTP’, ‘Bit rate’, for papers ranging from May 2003 and October 2001.
Created By Olufunke Olaleye
Last Modified on December 5, 2003