
Prepared for Prof. Javed I. Khan
Department of Computer Science, Kent State University
Date: December 2004
Abstract: In this survey different types of files indexing and
searching method is described. For each technique looked at this
survey will also look at an important aspect, that is, the relative
comparison between the techniques. From the traditional methods, a
method is also recommended in industry work-horse, for large databases
and web pages.
[Keyword]: Inversion, Inverted Indexing, Signature File, Clustering.
The proliferation of online text, such as on the World Wide Web and in databases, motivates the need for space-efficient index methods that support fast search. A great deal of textual information is available in electronic form, in databases and on the World Wide Web, and consequently, devising indexing methods to support fast search is a relevant research topic. Inverted lists and signature files are efficient indexes for texts that are structured as long sequences of words or keys.
This survey paper addresses only a small part of text retrieval, it will concentrate on different ways in which files are stored and searched. For each technique looked at this survey will also look at an important aspect, that is, the relative comparison between the techniques.
In a text database with a search pattern the whole database is searched until the required document is found. This method requires no space overhead and minimal effort on insertions and updates. The main disadvantage is the retrieval speed. Despite the existence of some fast string searching algorithms, scanning of a large database may take too much time.
This method uses an index. An entry of this index consists of a word along with a list of pointers. These pointers point to documents that contain this word. Many commercial systems have adopted this approach: STAIRS, MEDLARS, ORBIT, LEXIS, etc. The main advantage of the method seems to be its retrieval speed. However, it may require large storage overhead for the index. Moreover, insertions of new documents require expensive updates of the index.
The documents are stored sequentially in the "text file." Their abstractions are stored sequentially in the "signature file." When a query arrives, the signature file is scanned sequentially, and a large number of non-qualifying documents are discarded. The rest are either checked (so that the "false drops" are discarded) or they are returned to the user as they are. A document is called a "false drop" if it does not actually qualify in a query, although its signature indicates it does.
Similar documents are grouped together to form clusters. The documents are also stored in the same disk space. Clustering is the dominating access method in the literature of library science. The reason is that the emphasis in clustering is on the "relevance" queries, for example, "give me the documents that are relevant to 'information retrieval' (even if a document does not contain the above two words)." Papers on the performance analysis of clustering are mainly concerned with recall and precision and seem to ignore the space overhead, the retrieval speed, and the efficiency upon insertions.
To work in a large text database environment two most popular techniques that are deployed widely are inverted indexing and signature files. The two methods with the building of inverted and signature files will be discussed and will be compared in he following sections.
Index increases the speed and efficiency of searches of the document collection. Without any sort of index, users have to go through several documents to find out which document contains the desired term. For example if we consider the ‘Find’ operation in WINDOWS, it searches all the files of different directories for a specific file. With only a few thousand files on a typical laptop, a typical “Find” operation takes a minute or longer. But, a web search covers at least one billion documents. Considering we have a fast processor and high speed disk drives that enable a scan of one million documents per second, still sequential scan is simply not feasible. An inverted index over a collection of Web pages consists of a set of inverted lists, one for each occurring word (or index term). The inverted list for a term is a sorted list of locations where the term appears in the collection (pretty much like the index found in the back of this book that maps terms to page numbers).
In the research in building a distributed inverted index for a large collection of Web pages Garcia-Molina et. al. have introduced a pipelining technique for structuring the core index-building system that substantially reduces the index construction time.
The pipeline technique Gracia-Molina et. al. have developed minimizes the time required for different indexing phases. These phases are referred as loading, processing and flushing. The index building process executes on each indexer. The indexer takes stream of Web pages as input and produces a set of sorted runs. Each sorted run contains postings extracted from a subset of the pages received by the index-builder.
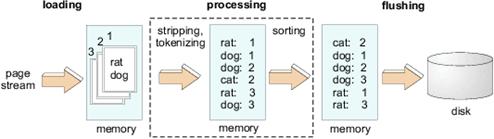
[Diagram courtesy Gracia-Molina et. al.]
During the loading phase, numbers of pages are read from the input stream. The processing phase involves two steps. First, the pages are parsed to remove HTML tagging, tokenized into individual terms, and stored as a set of postings in a memory buffer. In the second step, the postings are sorted in-place, first by term, and then by location. During the flushing phase, the sorted postings in the memory buffer are saved on disk as a sorted run. These three phases are executed repeatedly until the entire input stream of pages has been consumed. Loading, processing and flushing tend to use disjoint sets of system resources. Processing is obviously CPU-intensive, whereas flushing primarily exerts secondary storage, and loading can be done directly from the network, tape, or a separate disk. Therefore, indexing performance can be improved by executing these three phases concurrently. Since the execution order of loading, processing and flushing is fixed, these three phases together form a software pipeline.
Signature file approach is a well-known indexing technique for information access. In signature files the content of a record is encoded in a bit string called record signature. The resulting document signatures are sequentially stored in a different file which is much smaller than the original file and can be searched much faster. Two methods for signature extraction are discussed here.
The first method “Word Signature” suggests that each word in the document in hashed into a fixed length “f” bits. These bits are concatenated to form the whole document. For searching of a single word the signature of a search word is extracted and the documents are searched.
|
Document |
Bangladesh |
wins |
the |
WorldCup |
|
Word Signature |
0100 |
1000 |
1110 |
1011 |
|
Document Signature |
0100 1000 1110 1011 |
|||
In the previous example the document consists of four words and each word has a 4-bit word signature, here f=4. All the words are concatenated to build the whole document.
In this method each the documents are divided into logical blocks. A logical block is defined as a piece of text that contains a constant number D BL of distinct, noncommon words. Each such word yields a bit pattern of size F. These bit patterns are joined logically (OR) together to form the block signature. The concatenation of the block signatures of a document forms the document signature. Each word yields m bit positions (not necessarily distinct) in the range 1-F. The corresponding bits are set to “1”, and all the others bits are set to "0".
|
Word |
Signature |
|
Tree |
001 000 110 010 |
|
Root |
000 010 101 001 |
|
Block Signature |
001 010 111 011 |
For example, in the table, the word "Tree" sets to "1" the 3rd, 7th, 8th, and llth bits (m = 4 bits per word). In order to allow searching for parts of words, the following method is suggested: Each word is divided into successive, overlapping triplets (e.g., "Tr", "Tre", "ree", "ee", for the word "Tree"). Each such triplet is hashed to a bit position by applying a hashing function on a numerical encoding of the triplet.
Searching for a word is handled as follows: The signature of the word is created. Here the signature contains "1" in positions 3, 7, 8 and 11. Each block signature is examined. If the above bit positions (i.e., 3, 7, 8 and 11) of the block signature contain “1”, then the block is retrieved. Otherwise it is discarded.
The Inverted method is fast and relatively easy to implement and it supports synonyms easily, the synonyms can be organized as threaded list within the dictionary. The main disadvantage is the cost of updating and reorganizing the index if the environment is dynamic.
Optimization in index-building is not as critical as optimizing run-time query processing and retrieval but with a Web-scale index, index build time also becomes a critical factor for following two reasons:
Scale and growth rate: As the Web is large and growing rapidly the conventional build schemes become unmanageable, requiring huge resources and time to complete.
Rate of change: The rate of change in the Web is very high. Most commercial Web search systems employ rebuilding approach and it is critical to build the index rapidly to quickly provide access to the new data.
In the word signature files all the words are encoded in same bit length. So the less frequent and more frequent words in the document have the same bits. This causes unnecessary waste of space. If the frequency of the word is also considered and less occurring words are encoded with more number of bits and more frequent words are encoded with less number of bits then the size of the signature files will be reduced significantly. The response time is very high when the document is large. The Implementation is relatively simple. J. Zobel et al. had two text database systems implemented within their research group over a period of several years, which they used to compare the performance of inverted files and signature files.
For inverted files, reported index sizes are from 6 to 10% of the indexed data. These figures include storage of in-document frequencies (used in processing of ranked queries) and indexing of all terms, including stop-words and numbers. The space required by signature files depends on the signature width, and on whether blocking is used. Quoted sizes are 25 to 40% of the indexed data
|
|
Signature Width |
Size in Megabytes |
% |
|
Inverted file |
NA |
16.2 |
6.1 |
|
Word Signature |
44,492 |
143.6 |
53.8 |
|
Block Signature |
12,204 |
65.5 |
24.5 |
Table: Index Parameters (Signature Width, Size in Megabytes, Size as Percentage of Size of Original Data)
Performance in different techniques is shown in the following tables. The table shows the time spent retrieving and processing index information, that is, the time spent fetching and resolving inverted lists or signatures in order to generate a list of possible or actual answer documents.
|
Query |
Inverted file |
Word Signature |
Block Signature |
|
First |
0.09 |
0.35 |
0.16 |
|
Second |
0.21 |
0.38 |
0.28 |
|
Third |
1.33 |
3.76 |
4.22 |
|
Fourth |
1.12 |
0.83 |
0.54 |
|
Fifth |
0.50 |
2.50 |
1.94 |
Table: Index Processing Time (Elapsed Time; Seconds)
The next table shows the total time (including the index processing times listed in the previous table) spent retrieving answers, and, in the case of signature files, time spent retrieving, processing, and eliminating false matches.
|
Query |
Inverted file |
Word Signature |
Block Signature |
|
First |
0.49 [9] |
1.24 [11] |
0.52 [9] |
|
Second |
1.16 [25] |
4.11 [36] |
5.69 [88] |
|
Third |
2.52 [32] |
12.26 [92] |
10.80 [109] |
|
Fourth |
0.33 [1] |
0.83 [2] |
0.37 [1] |
|
Fifth |
1.68 [11] |
3.62 [19] |
4.14 [54] |
Table: Query Evaluation Speed (Average Elapsed Time in Seconds) and Number of Documents Retrieved (i.e., Average False and True Matches; Shown in Square Brackets)
For typical document indexing applications, as well as web page indexing current signature file techniques do not perform well compared to current implementations of inverted file indexes. Signature files are much larger; they are more expensive to build and update; they require that a variety of parameters be fixed in advance, involving analysis of the data and tuning for expected queries; they do not support proximity queries other than adjacency; they support ranked queries only with difficulty; they are expensive for disjunctive queries; they are highly intolerant of range in document length; their response time is unpredictable; they do not allow easy addition of functionality; they do not scale well; and, most important of all, they are slow. Even on queries expressly designed to favor them, signature files are slower than inverted files.
Conclusion:
The survey has discussed the traditional methods for Information Retrieval, along with some recent developments that try to capture semantic information. From the traditional methods the inverted file is recommended in industry work-horse, for large databases and web pages.
"This survey is based on electronic search in IEEE
Intracom proceeding, ACM Portal and their citations. The ACM digital
portal was searched using key words 'indexing', for papers ranging from
September 2004 and December 1995".